Introduction
fluxEngine consists of three main components:
Data Acquisition and driver abstraction: leverage the driver abstraction framework built in to fluxTrainer that allows accessing various instruments, most notably hyperspectral cameras, in a standardized manner. Various different device models are supported, and all may be accessed via a common API.
Data Standardization: allow the user to obtain standardized data from various instruments. Software corrections that may be required for the specific instrument (e.g. smile correction for hyperspectral pushbroom cameras) can be applied, as well as accessing the data in a standardized memory layout. This allows the user to record data from instruments in a standardized manner, as well as prepare it for either custom processing by the user or for further processing via fluxEngine.
Data Processing: leverage the data processing framework built into fluxTrainer to process data using models created in fluxTrainer.
There are three main use cases for fluxEngine:
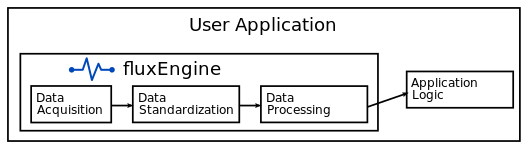
Acquire standardized data from instruments, such as hyperspectral cameras. The user may use this to record the data for later processing, or perform their own custom processing, such as via neural networks.
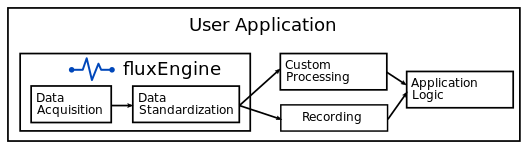
Acquire data from instruments and process them via a model created in fluxTrainer. This allows the user to leverage the data processing technology built into fluxTrainer in a custom application.
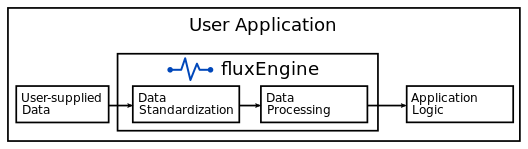
Import hyperspectral data and processing it directly.
License File
In order to initialize fluxEngine, a license file must be provided at the beginning. A license for fluxEngine can be tied to one of the following things:
A given machine and must contain an identifier that uniquely identifies the system fluxEngine is to be run on.
A given instrument device and must contain the serial number of the corresponding instrument. In that case the user must connect to the instrument in question before being able to process data, even if data processing is to happen with offline data.
A dongle.
The various features of fluxEngine may be licensed separately. For example, a license may allow the user to acquire data via fluxEngine in a standardized manner from hyperspectral pushbroom cameras, but not use models from fluxTrainer to process them. Or a license may allow the user to process hyperspectral data, but not acquire any data via the driver abstraction layer.
Driver Abstraction
fluxEngine comes with a powerful driver abstraction layer that provides the user with a standardized interface for accessing various devices supported by fluxEngine.
fluxEngine drivers are loaded in a separate process to isolate them from the main executable. This has the advantage that if there is an issue with the driver (it crashes, for example, due to some hardware issue) then the main executable is not affected by this.
The driver abstraction framework consists of two main components: the driver themselves and the executable that loads them in a separate process. There are two methods of communication between the driver isolation executable and fluxEngine: for actions related to the driver (get a parameter, set a parameter, start acquisiton for an instrument, etc.) the communication happens via a pipe. For the transfer of data from an instrument to fluxEngine the data is placed in a shared memory segment by the driver for the best performance and lowest latency. This all happens transparently to the user.
Further details on how to deploy drivers in combination with fluxEngine are provided in their own chapter.
Data Processing
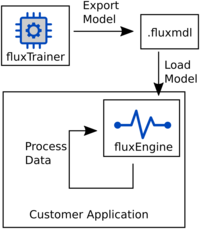
fluxEngine requires runtime models that have been created via the
fluxTrainer data modelling software. Using the
Export Runtime/Engine Model feature of fluxTrainer, one may create
.fluxmdl files that contain the information required to process
data. fluxEngine can load these files, and once supplied with input
data, data processing may begin.
Programming Languages
The primary public API of fluxEngine is provided in form of a native C API. This ensures the following:
The programming interface remains binary-compatible across versions, so that programs don’t need to be recompiled when fluxEngine is updated
It is possible to call fluxEngine from as many programming languages as possible, as most languages provide the means to wrap C APIs.
C++ Support
fluxEngine comes with a header-only C++ wrapper for fluxEngine’s C API that allows the user to interact with fluxEngine using C++. As the library is header-only this should work with any compliant C++ compiler that supports C++11. The API adds more features if the compiler also supports C++17.
Python Support
fluxEngine comes with a Python 3.x extension that wraps fluxEngine’s C API. This allows the user to interact with fluxEngine using Python. Prebuilt extension packages are provided for Windows systems for various Python versions. The source code for the Python extension is also provided to allow the user to build the extension for other operating systems, or if they use a non-standard Python version on Windows.
The Python extension integrates with NumPy and uses NumPy arrays to exchange data with the user.
Data Storage
As users of fluxEngine will supply it with input data, and then read out output data, it is important to understand how data has to be stored in memory so that fluxEngine can understand it.
Tensors
The most important type of data that may be stored are tensors. A tensor contains a number of scalar values that may uniquely be addressed with a set of indices. The order of a tensor describes how many indices are required to address an individual element:
A simple scalar value, that is, a single number, is a tensor of order zero that does not have any indices.
A vector of scalar values is a tensor of order one.
A matrix or image is a tensor or order two.
A hyperspectral cube is a tensor of order three.
Indexes in the underlying C API start counting at 0, so a vector with three elements will be indexed by the indices 0, 1 and 2.
As computer memory is linear, higher-order tensors have to be linearized to be accessible.

For example, a tensor of order 2 may be linearized in two different manners:
Row-major (C style), where incrementing the right-most index of a given tensor by 1 increments the memory address where that element is stored by one scalar element
For example, in a tensor of order 3, going from
(12,7,8)to(12,7,9)will move in memory by a single scalar element.Column-major (Fortran style), where incrementing the left-most index of a given tensor by 1 increments the memory address where that element is stored by one scalar element
For example, in a tensor of order 3, going from
(12,7,8)to(13,7,8)will move in memory by a single scalar element.
Note
All tensors that fluxEngine processes are in row-major order.
Strided Data Storage
In the previous examples, tensors were stored contiguously in memory. This means that any element within the memory region of the tensor corresponds to an actual entry in the tensor.
In some cases it may be advantegeous though to store tensors with gaps in their storage. For example, it might be advantegeous to start rows of images on aligned memory addresses.
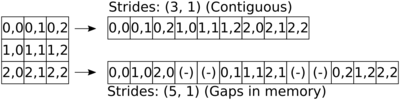
Each dimension of a tensor has a given stride. In fluxEngine’s notation a stride indicates the number of scalar elements that need to be multiplied to the index when calculating the linearization.
For example, if a tensor of dimensions (6, 10, 3) is stored
contiguously in memory, it will have the strides (30, 3, 1), as
linearization of an index (i, j, k) is done via the formula
30 * i + 3 * j + 1 * k.
A gap may occur if the stride for a given dimension is larger than the
size of the previous dimension, multiplied with the stride of the
previous dimension. For example, it would be possible to store the
aforementioned tensor with dimensions (6, 10, 3) with a stride
structure of (80, 4, 1), creating gaps.
Note
Output data provided by fluxEngine will always be contiguous in memory.
Warning
fluxEngine is capable of processing input data that
contain non-trivial strides, but only if the right-most
stride is always 1, indicating that the inner-most
dimension is contiguous.
Hyperspectral Cubes
Hyperspectral cubes are tensors of order three: two spatial dimensions x and y, as well as a dimension for the wavelengths, λ.
This can be thought of in two ways:
For each pixel in a given image, a full vector of values exists, one for each wavelength λ.
For each wavelength λ there is an entire image stored within the cube.
There are three main storage orders that describe how a hyperspectral cube is stored in memory:
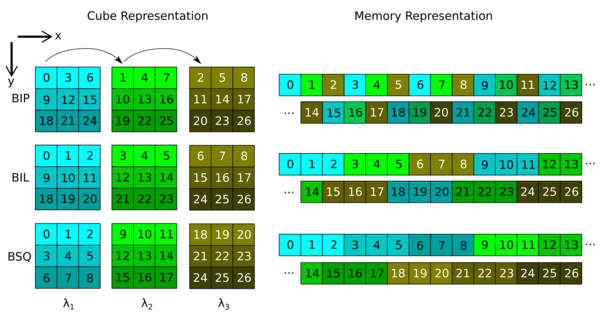
Band interleaved by pixel (BIP): the values corresponding to the different wavelengths for a single pixel are stored next to each other, and this is repeated for each pixel. In our notation, an index into this tensor would be specified via
(y, x, λ).Band interleaved by line (BIL): for a given wavelength the values of all pixels of a given line are stored next to each other, this is then repeated for each wavelength, and then for all lines of the cube. In our notation, an index into this tensor would be specified via
(y, λ, x).Band sequential (BSQ): a full image for any given wavelength is stored contiguously, this is then repeated for each wavelength. In our notation, an index into this tensor would be specified via
(λ, y, x).
Note
A note on spectrometers: While fluxEngine does not have a specific API of dealing with individual spectra, it should be considered that a spectrometer could be seen as a camera that creates a hyperspectral cube with just a single pixel in both x and y directions.
PushBroom Cameras
PushBroom Cameras are one of the most common hyperspectral cameras available. They use a 2D image sensor to image a single line, where diffraction optics are used to map wavelengths onto one of the dimensions of the 2D sensor.
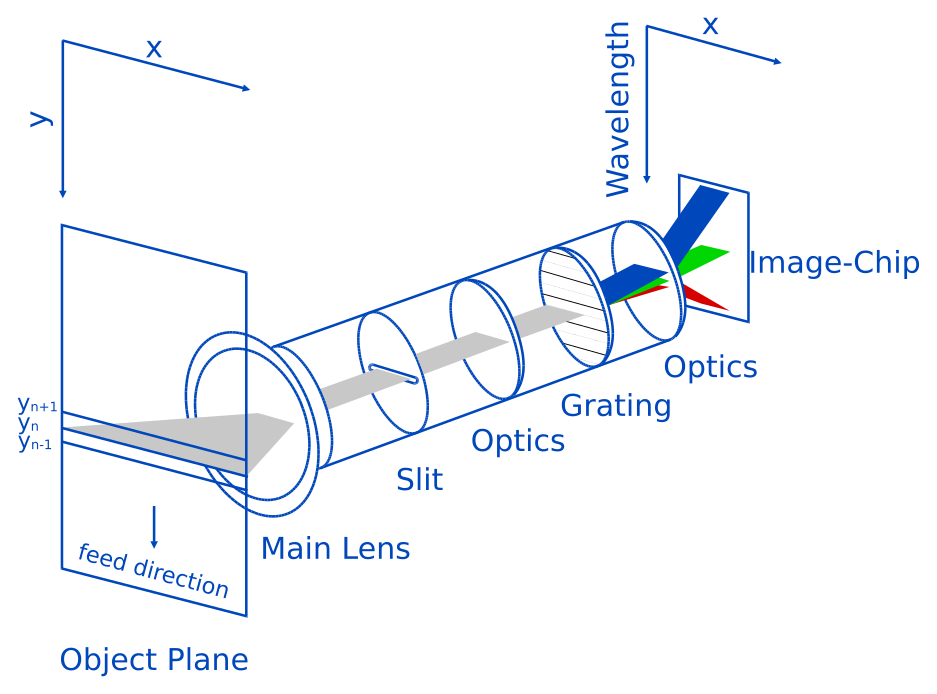
Each time the camera records a frame, a single line is imaged spatially, but for each spatial pixel wavelength information is provided. For example, a typical PushBroom camera that captures visible light will have around 200 wavelengths in a range of 400nm to 1000nm, and return that information for each spatial pixel along the line it is set up to image.
To obtain a full image (and hence a hyperspectral cube) from this kind of camera, one typically moves the object that is to be imaged, either by placing it on a stage that can be moved, or by placing it on a conveyor belt.
There are two different ways PushBroom cameras may be set up: they could either have the wavelengths projected onto the y direction of the image sensor, with the x direction of the image sensor containing the spatial information (as is illustrated in the image above), or vice-versa.
As the image created by a PushBroom camera only contains a single line, image-based operations (such as detecting objects) cannot be performed only during the processing of a single frame; the operations have to track their current state and combine sequential frames. This also means that for example detected objects will only be returned to the user once the entire object has passed beneath the camera.
Referencing
When taking hyperspectral images, in most cases it is useful not to consider the raw intensities returned by a camera, as they will depend strongly on the specific lighting conditions. These have a much larger effect on hyperspectral cameras than they do on regular cameras.
In order to become independent of the specific lighting conditions, one typically performs a measurement with a white reference material, such as optical PTFE or barium sulfate. This may then be used to calculate reflectances via the fomula:
R = I / W
Here, R are the reflectance values (for each pixel), I are the
intensities from the camera and W are the intensities of the white
reference that was measured.
Additionally, if the camera sensor has a significant dark current due to sensor noise, a dark reference (using a shutter, for example) may be used to subtract the dark current for an even more accurate result,
R = (I - D) / (W - D)
Here, D denotes the intensities of ther dark reference that was
measured.
In models created in fluxTrainer the user can select whether they want to work in intensities or reflectances.
If a model is in intensities, the user must provide the intensities recorded with the camera to fluxEngine, but nothing further.
If a model is in reflectances, the user has a choice: they can either provide fluxEngine with pre-calculated reflectances, or provide fluxEngine with raw intensities, if they also provide a white reference measurement (and possibly a dark reference measurement) during setup, so that fluxRuntime may perform this operation automatically.
Multi-Threading
fluxEngine supports various ways of multi-threading.
Parallelization of Data Processing
Processing fluxEngine models may be done using more than just the single thread the processing is initiated with. fluxEngine has the ability to start background threads that will automatically be used to speed up data processing.
It is up to the user to decide how many background threads should be started. A good rule of thumb is to never use more than there are physical cores in the computer. (Since the workload in the different threads is very similar to each other, using additional logical cores provided via HyperThreading / SMT will typically not speed up processing. Though those core might be useful for other tasks that are executed by the operating system or background processes.)
The user has to decide how many threads to use before processing data.
This is done via the thread creation functions,
fluxEngine_C_v1_create_processing_threads(),
Handle::createProcessingThreads(),
or
Handle.createProcessingThreads().
If these are not called processing will by default occur
single-threaded in just the thread where it has been requested.
Processing Multiple Models
It is also possible to process multiple models at the same time. Each processing context (the abstraction used to process data for a given model) is associated with a so-called processing queue set. By default there is a main processing queue set associated with the handle of fluxEngine.
It is also possible to create additional processing queue sets that are independent of the main set. Each processing queue set (including the main one) will its own set of background threads. The user may determine how many there are for each set.
Each processing queue set may only process one thing at the same time. If processing of data with a second processing context is attempted while the current processing context is still busy, the second thread will wait for the first to be finished.
However, if the second processing context is associated with a different processing queue set, it will process data independently of the first processing context that uses another processing queue set.

Functionality Overview
The following diagram illustrates how fluxEngine can be used to process data. Functions of fluxEngine where data is passed along for processing are black solid arrows. Black dotted arrows describe how specific data is used as a white (or dark) reference to initialize a processing context All contexts that process data with a model are shown in dark green. Models loaded from disk are shown in dark red.
All data structures and operations that the user must handle themselves entirely (and are outside of fluxEngine) are in dark blue.

The source* marking indicates that the data has to be provided to
the processing context via setSourceData() and then invoke the
processing in the context via processNext(). (The precise names
of these methods will depend on the language used.
In the following the most common scenarios for the usage of fluxEngine will be discussed. For all cases except when there are external SDKs involved, the examples that correspond to this will be referenced.
Recording an ENVI cube from a camera supported by fluxEngine
When using a camera that is supported natively by fluxEngine, the user can obtain buffers from the camera that contain a HSI PushBroom line each.
When a white reference is desired, these buffers can be concatenated
together by using a BufferContainer data structure provided by
fluxEngine. That can then be used as the input when creating an
InstrumentRecordingContext.

After the recording context has been initialized, it can be used to
standardize data obtained from the camera. (For example, this will
perform any software corrections that may be required for that specific
camera.) That data can then be concatenated into a cube by using
another BufferContainer. From this a MesaurementList can be
created, which can then be saved on disk in ENVI format:

The example Record an ENVI Cube in Intensities with References from a PushBroom demonstrates the usage of fluxEngine in this scenario.
Processing data line by line from a camera supported by fluxEngine
As with the recording example, the user can obtain buffers from a camera natively supported by fluxEngine that each contain a HSI PushBroom line.
Again a white reference may be measured and concatenated together
in a BufferContainer. The white reference together with a model
loaded from disk can be used as input when creating an
InstrumentProcessingContext.

After the processing context has been initialized, it can be used to process data obtained from the camera line by line. The result of that model is returned in output sinks associated with the processing context (and are dependent on the used model). It is up to the user to decide what to do with the processed data.

The examples Process Data from a PushBroom Device in a Model (for a pixel-based output) and Process Data from a PushBroom Device With an Object Detector (for an object list output) demonstrate the usage of fluxEngine in this scenario.
Note
Even though the data is processed line by line, fluxEngine is still able to detect objects in a line camera stream, because it keeps track of state between lines.
Loading an ENVI cube and processing the entire cube
fluxEngine can also be used in offline mode without being connected to a camera. [1] A user might want to load an ENVI cube from disk and process it using a model.
For this the user first needs to create a processing context suitable for that model and that cube. fluxEngine provides a direct function to create a processing context from a model and a cube that will be able to process that cube.

Afterwards the user can use the cube as source data for the same processing context and process it. It is possible to process different cubes with the same processing context, as long as they have exactly the same structure.

The example Read ENVI Cube and Process using Model shows how this is done using fluxEngine’s simplified API. Another example Read ENVI Cube and Process using Model (Explicit Variant) shows how this can be done by manually telling fluxEngine about the structure of the cube that has been loaded, instead of using the simplified API for this.
Recording an ENVI cube by obtaining data from an external SDK
A user might also use a third-party SDK to interface with a camera that is not supported by fluxEngine natively. In that case it is possible to use the data obtained by the third-party SDK as input for fluxEngine. The structure of this data has to be provdied by the user manually to fluxEngine.
If the third-party SDK provides the user with HSI PushBroom lines,
it is up to the user to concatenate those lines themselves to a
HSI cube organized in memory managed by the user themselves. Such
a HSI cube may then be used as input to create a MeausrementList
object in fluxEngine, which fluxEngine can then save to disk:

(Optionally the user may also record a separate HSI cube to use as
a white reference and supply that when creating the
MeausrementList. In that case a white reference ENVI cube will be
stored next to the ENVI cube when saving the MeasurementList.)
There is no example in fluxEngine’s official documentation for this, because the details would depend on the specific SDK that is being used.
Processing data obtained by an external SDK line by line
In addition to recording data, fluxEngine can also be used to process data line by line as obtained by a HSI PushBroom line camera. In that case, for most models the user must still provide a white reference when creating the processing context. This can be done in two ways:
The user records multiple HSI lines with the external SDK and concatenates them themselves, and provides this memory area to fluxEngine.

The user loads a HSI cube from disk and uses that as the white reference for creating the reference.

Warning
Since fluxEngine always represents HSI cubes in the BIP storage order,
[y, x, λ], regardless of how they were stored, using a cube loaded with fluxEngine directly will only work out of the box if the HSI camera has the wavelengths in the x direction of the sensor, and the spatial dimension maps to the y direction of the sensor. Since many HSI cameras use the opposite orientation, a cube that may be used as a white reference for those types of cameras would have to be in BIL storage order,[y, λ, x]. In that case it would be up to the user to perform the transposition themselves before using it for creating a context that is supposed to process HSI lines of the structure[λ, x](i.e. the LambdaY storage order).If the user loaded a BIL cube manually themselves (without using fluxEngine to do so), then this does not apply.
After that processing context has been created, the lines obtained from the external SDK can then be passed to fluxEngine.

There is no example in fluxEngine’s official documentation for this, because the details would depend on the specific SDK that is being used.